|
驅動中國2017年10月19日消息 據英國Nature雜志報道,谷歌旗下的AI子公司DeepMind本周發布了新一代AlphaGo程序,這套AI程序被命名為“AlphaGo Zero”。它可以通過一種“強化學習”的機器學習技術,自學多種游戲,僅經過三天訓練便擊敗了前代的AlphaGo Lee。
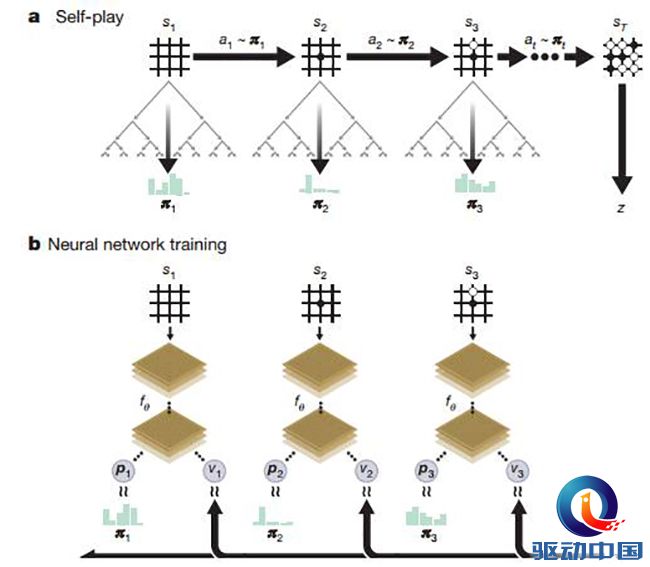
據悉,AlphaGo Zero能利用強化學習技術(Reinforcement Learning),大幅提高自學能力。在三天時間內自行掌握了圍棋的規則,還自行創造了更優的棋路。在這時間內未獲得人類的幫助,自行學習先進概念,選擇有利位置和序列戰勝了曾擊敗李世石的AlphaGo Lee。而經過40天的訓練,自學了2900萬種游戲,AlphaGo Zero戰勝了曾擊敗柯潔的AlphaGo Master。 此前,AlphaGo Lee及AlphaGo Master兩代在接受訓練時,觀摩學習了人類專業或業余棋手對弈的海量棋局。而AlphaGo Zero則沒有獲得這樣的訓練,它只是進行數百萬次的自我對弈 ,從中學習棋藝。
DeepMind公司表示,這一套新的程序核心就是連接在一起的人造神經元。AI程序會觀察旗子在棋盤上的位置,并推算下步棋怎么走及獲勝的概率。不過,AlphaGo Zero相比上代版本是一個更簡單的程序,接受訓練的數據更少,承載的計算機設備體積更小。 AlphaGo的首席研究員David Silver表示,“由于未引入人類棋手的數據,AlphaGo Zero遠比過去的版本強大,我們去除了人類知識的限制,它能夠自己創造知識。”
研究團隊表示,AlphaGoZero的棋藝也是從一開始糟糕透頂到缺乏經驗的業余棋手,最后成為圍棋高手。它的面世是AI發展的里程碑,因為它是完全沒有人類棋手數據做指引的情況下,進行自我學習進化。當然,除過圍棋之外,AlphaGo Zero目前正在研究的一個課題就是關于藥物方面蛋白質如何折疊的問題,將來有望取得突破。
|


精彩科技視頻



科技產品報價







